端到端神经网络架构:特斯拉算力硬件升级路径解析
特斯拉FSDV14.3版本的内测推进,标志着其端到端神经网络架构进入了新的应用阶段。根据技术参数分析,该版本相较于V13版本,在参数量级上实现了十倍的增长,这意味着系统对环境感知与决策逻辑的复杂性处理能力得到显著提升。然而,这种高性能的实现,对底层算力架构提出了硬性要求。根据特斯拉的技术白皮书及公开披露信息,仅有搭载AI4(HW4.0)硬件平台的车型具备运行该版本的算力基础,而AI3(HW3.0)平台则被限制在Lite版本范围内。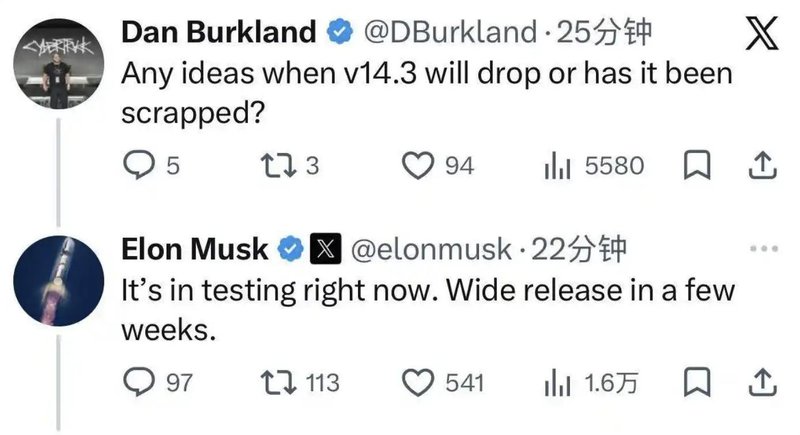
算力门槛与行业迭代逻辑
行业内的算力竞赛已经进入白热化阶段。从单一的芯片性能堆叠,转向以神经网络架构为核心的算力优化,是当前自动驾驶领域的主流趋势。特斯拉通过自研芯片与软件算法的深度耦合,构建了一套高壁垒的生态系统。这种架构设计的优势在于能够最大化利用算力,但劣势同样明显,即对老旧硬件的兼容性较差,导致硬件平台一旦落后,便无法通过软件升级获取完整功能。
这种硬件绑定的策略,本质上是加速车辆生命周期的手段。在汽车行业,硬件预埋是常见的技术预判,但算力需求的增长速度往往超越了预期。企业在进行硬件配置时,需要平衡成本与未来技术储备,而特斯拉通过高算力平台的快速换代,实际上是在倒逼整个生态的升级。
对于消费者而言,这意味着车辆的保值率与智能化程度直接挂钩。在选购车型时,关注算力平台的冗余度,已成为判断车辆长期价值的关键指标。那些在早期预留了高算力芯片的车型,在后续的软件升级中表现出了明显的生命力,而算力不足的车型则面临着功能被阉割的风险。
情景模拟与解决方案
假设一位车主在使用搭载AI3平台的车型,在面对FSDV14.3推送时,系统将自动识别硬件限制,推送Lite版本。这种情景模拟揭示了一个残酷的现实:算力决定体验。为了解决这一痛点,车主通常有两条路径:一是接受功能的降级,继续使用现有系统;二是考虑置换搭载AI4平台的新车。从数据验证来看,搭载AI4平台的车型在处理复杂路况、识别异形障碍物等方面的准确率,显著高于AI3平台。
未来的自动驾驶发展,将更加依赖于海量数据的闭环训练。特斯拉通过全球范围内的车队数据采集,持续优化其神经网络模型。这种数据驱动的模式,使得其智驾能力呈现出非线性的增长曲线。对于国内竞争对手而言,如何利用本土化的道路数据,构建同样高效的训练闭环,是打破特斯拉技术垄断的关键所在。
综上所述,FSDV14.3的落地不仅是一次软件更新,更是一场关于算力与架构的行业洗牌。企业需要重新审视硬件预埋的策略,而消费者则需要更加审慎地评估智能化配置的长期收益。自动驾驶的终局尚未到来,但技术路径的竞争已然进入深水区。